도서 목록을 웹스크래핑 프롬프트를 이용해 도서정보를 수집하는 방법에 대해서 배웠다.
예스 24, 알라딘, 교보문고의 도서 수집을 할 것이다.




웹스크래핑 프롬프트 공식
- HTTP 요청정보
- 페이로드 정보
- 응답의 일부(HTML 혹은 JSON)
a. HTML 일 때는 마우스오른클릭 > 블록선택 > copyOuterHTML
b. JSON 일 때는 미리보기 > JSON 처음부터 원하는 도서 정보가 있는 첫번째 책 정보까지 복사 붙여넣기
c. 전체 HTML이나 JSON을 복사하지 않는이유 => 토큰수 문제(==글자수 제한) - 각각 복사한걸 지피티에 붙여넣으면 총 3개 -> 전체 데이터 목록을 HTTP요청으로 받아서 파싱하고 판다스 데이터프레임으로 만들어서 CSV로 저장하고 수집하는 코드 작성해줘 라고 입력한다.
- 구글 코렙으로 실행



- 스타벅스 전국 매장정보 수집과 분석
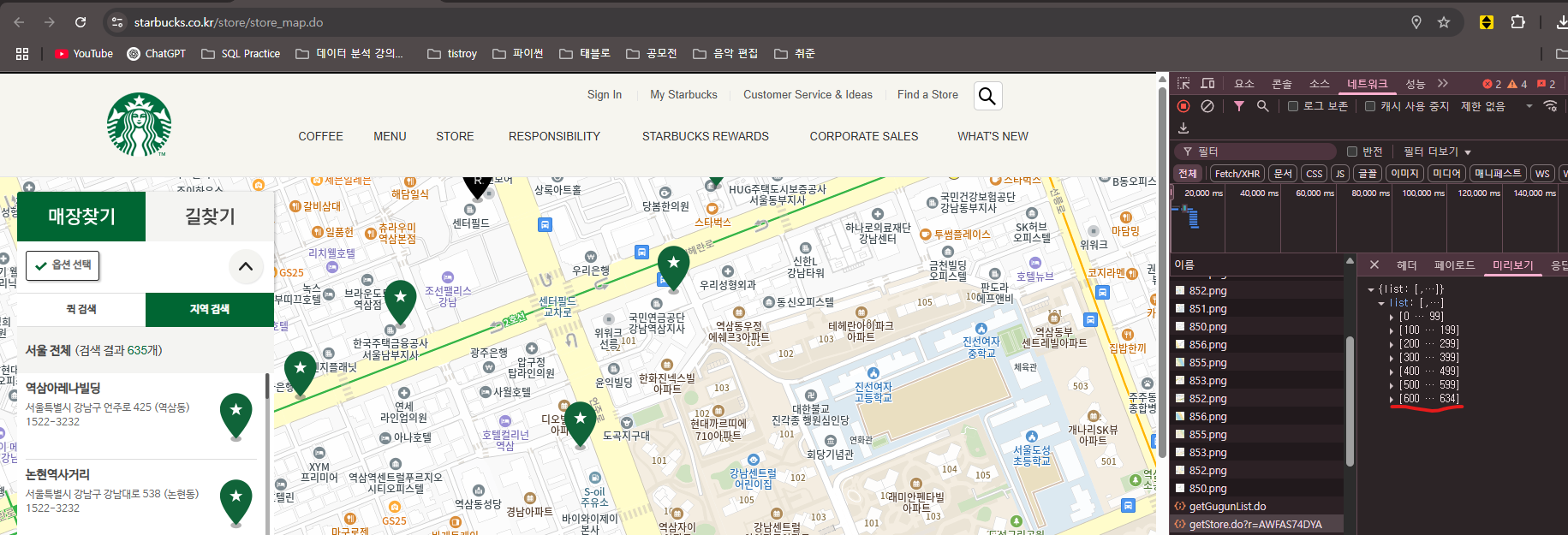
위 코드를 변경해서 01번부터 17번까지 반복문을 통해 전국 매장을 수집하도록 코드를 다시 작성 하고 전체 수집 이후에는 데이터프레임에서 모두 같은 값으로 되어 있는 컬럼은 제외하고 데이터 프레임을 csv 파일로 저장 할것
# 시도 코드 목록 ("01" ~ "17")
sido_codes = [f"{i:02d}" for i in range(1, 18)] (리스트 컴프레이션)
(전국 매장 명령어)



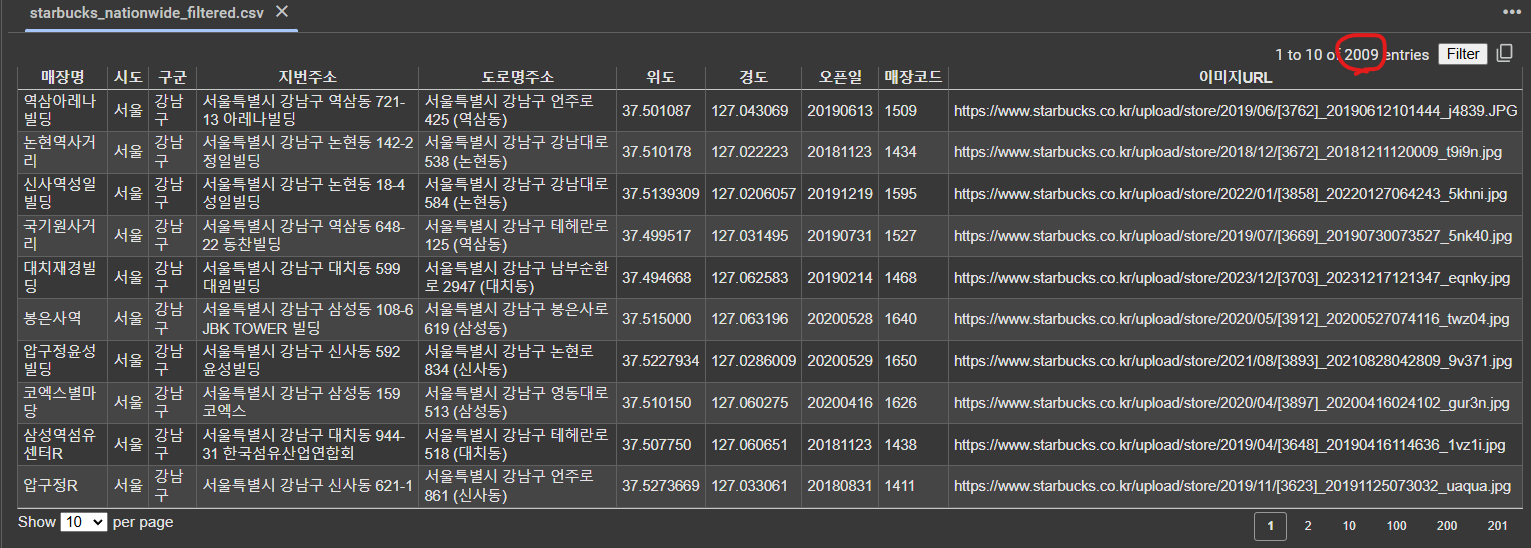
- yes24 데이터를 sqlitedb 로 수집하기
https://www.yes24.com/product/category/display/001001003031
- 전체 페이지 수집하고 도서 목록에 대한 응답의 결과가 1개보다 작을 때까지 마지막 페이지까지 수집하도록 할 것
- 페이지당 120개씩 도서를 가져오도록 할
- sqlitedb 사용해서 테이블에 저장하도록 할 것
(데이터베이스를 사용하면 중간에 상태값 업데이트 등에 대한 작업이 좀 더 유리함) - 작업 →
명령어) 위에서 수집할수 있는 도서정보 모두 수집하고 판매지수와 상세페이지 주소 포함하고 오류에 대한 예외처리도 추가하고 텍스트 데이터를 수치데이로 정제하는 작업을 하지말고 원본 데이터 그대로 수집할 수 있는 코드로 작성sqlitedb 로 매 페이지마다 저장하도록 파이썬 코드 작성, 반복문은 while 문으로 대체하고 코드 리팩토링(좀 더 보기좋게) ....-> 수집중 /... yes24 도서를 수집하되 페이지마다 sqlitedb로 저장 -> 상세페이지 주소, 판매지수도 포함하도록 함
db브라우저 설치 후 받은 파일 업로드(수집 완료 !)
✅ 1. 정의
📌 토픽모델링 (Topic Modeling)
- 정의: 문서 집합 내에 **잠재된 주제(Topic)**를 자동으로 추출하는 기법. 문서의 단어 분포를 바탕으로 주제를 구성하고, 각 문서가 어떤 주제들로 이루어졌는지 확률적으로 분석함.
- 대표 알고리즘: LDA(Latent Dirichlet Allocation), NMF(Non-negative Matrix Factorization)
- 목적: 대량의 텍스트 데이터에서 주제별로 분류하거나 핵심 토픽을 도출하여 인사이트를 얻는 것
📌 군집화 (Clustering)
- 정의: 데이터 간의 유사도를 기준으로 비슷한 데이터끼리 **그룹(Cluster)**으로 나누는 비지도 학습 기법. 사전에 레이블이 없는 데이터를 자동으로 분류함.
- 대표 알고리즘: K-Means(k 평균 -가장 대표적), DBSCAN, Hierarchical Clustering
- 목적: 데이터의 구조를 이해하고, 데이터 유형별 분류 및 집단 특성 분석
📌 유사분석 (Similarity Analysis)
- 정의: 두 데이터(문서, 문장, 단어 등) 간의 **유사도(Similarity)**를 수치화하여 비교 분석하는 기법. 코사인 유사도, 자카드 유사도, 유클리디안 거리 등을 활용.
- 대표 방법: Cosine Similarity, Jaccard Index, Euclidean Distance
- 목적: 추천 시스템, 문서 검색, 중복 문서 판별, 분류 기준 설정 등
비교표
항목토픽모델링군집화유사분석
| 목적 | 문서 내 숨겨진 주제 도출 | 비슷한 데이터의 자동 분류 | 두 데이터 간 유사도 측정 |
| 분석 대상 | 주로 문서 (텍스트 데이터) | 다양한 형식의 데이터 | 문서, 문장, 단어 등 |
| 결과 | 문서별 토픽 분포, 토픽별 주요 단어 | 데이터 군집 (Cluster) | 유사도 점수 (0~1 등) |
| 알고리즘 예시 | LDA, NMF | K-Means, DBSCAN | Cosine, Jaccard, Euclidean |
| 활용 예시 | 여론 분석, 콘텐츠 분류 | 고객 세분화, 이미지분류, 문서 분류, 상품 추천 | 검색 결과 정렬, 중복 탐지, 상품 추천 |
| 학습 방식 | 비지도학습 | 비지도학습 | 비지도/계산 기반 |
- 수집한 데이터 분석, 머신러닝 기법을 활용해서 유사도분석, 토픽모델링, 군집화
- 토픽모델링
- colab 에서 토픽모델링으로 주요 토픽별 키워드 추출
- 해당 키워드를 ChatGPT 로 불용어 제거 후 리포트 생성하기
- napkin 에 ChatGPT의 결과를 붙여 넣고 번개표시로 인포그래픽 생성


결과 -> 토픽 모델링 시각화



- 군집

(다음시간에)
- 유사도 분석
- 랭체인 분
- 위 분석 내용을 바탕으로 보고서 작성
'수업 일지' 카테고리의 다른 글
| 13주차 정리 (0) | 2025.03.27 |
|---|---|
| 12주차 정리 (0) | 2025.03.12 |
| 9주차 정리 (0) | 2025.02.15 |
| [Python Analysis] EPL 데이터 분석을 통한 토트넘 연대기 2 (0) | 2025.02.12 |
| [Python Analysis] EPL 데이터 분석을 통한 토트넘 연대기 1 (0) | 2025.02.12 |